
Introduction
For a long time, DevOps was treated as the answer to software delivery friction. If development and operations shared responsibility, automated more of the pipeline, and communicated earlier, teams could ship faster and more reliably. That logic still holds. The problem is that it does not scale cleanly on its own.
As organizations grow, the number of tools, environments, security controls, deployment patterns, and infrastructure decisions grows with them. At some point, asking every product team to navigate that complexity directly stops being empowering and starts becoming wasteful. Engineers spend more time learning platform internals than shipping product changes. Operations teams turn into ticket routers. Standards drift. Delivery gets slower even though everyone is supposedly doing DevOps.
This is the point where platform engineering becomes relevant.
Platform engineering is not the replacement for DevOps. It is the operational discipline that makes DevOps sustainable at scale. Google Cloud describes DevOps as the cultural goal and platform engineering as the practical way to deliver that goal through an internal developer platform, or IDP, with self-service golden paths. That framing is useful because it separates philosophy from execution.
The useful question in 2026 is no longer "DevOps or platform engineering?" The better question is: when does your organization need a dedicated platform product instead of asking every team to assemble its own delivery stack?
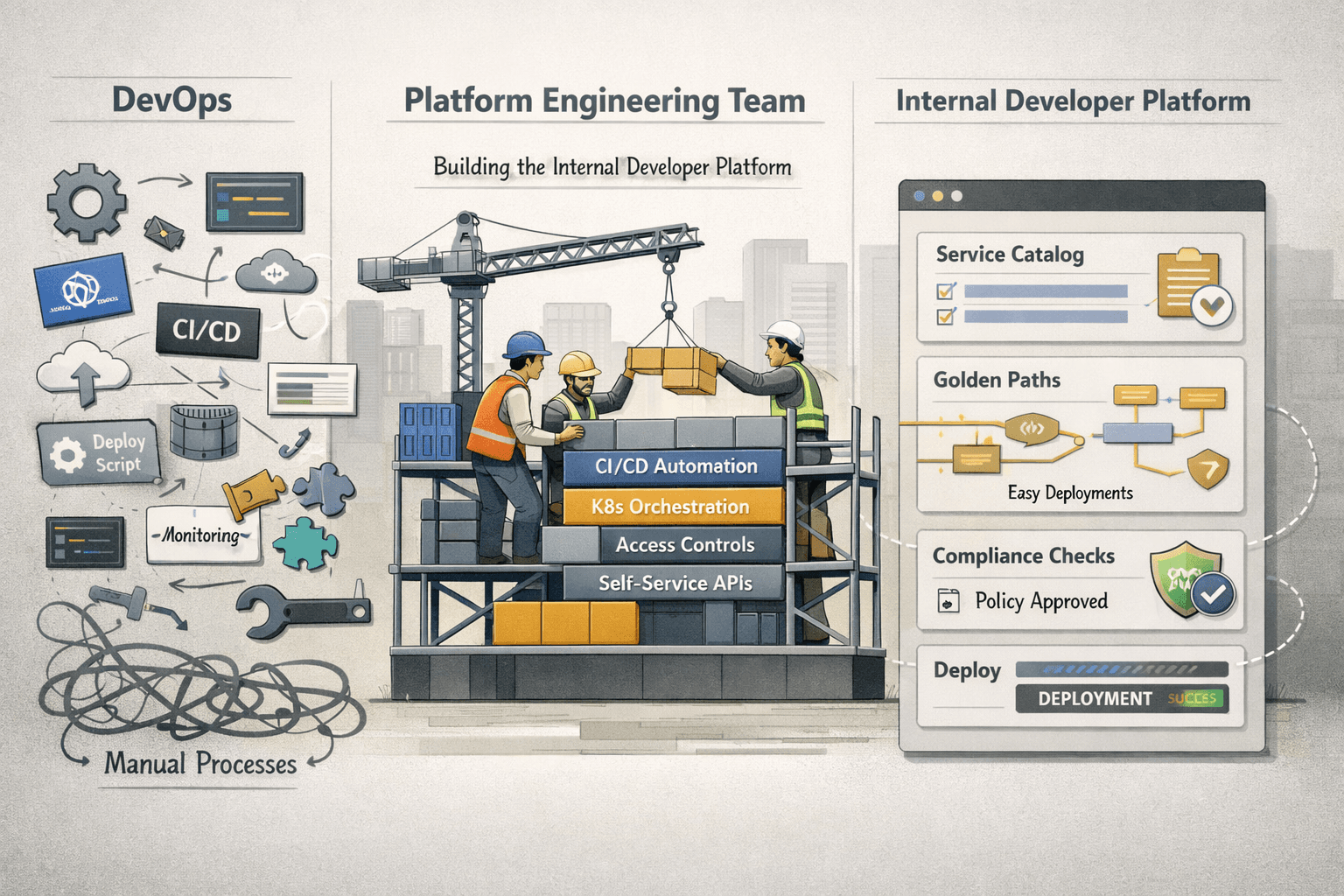
Core Content
DevOps is the goal, platform engineering is the system
The most productive way to compare the two is to stop treating them as competitors.
DevOps is a cultural and operational model. It emphasizes collaboration between development and operations, shared ownership, automation, and fast delivery of customer value. Platform engineering is a specialized discipline focused on building and maintaining the internal platform that makes those outcomes easier to achieve consistently.
Google Cloud states this distinction directly: DevOps is the "why," while platform engineering is the "how" for larger organizations. That tracks with what engineering teams experience in practice. DevOps tells you to automate and reduce handoffs. Platform engineering decides which workflows should be standardized, how those workflows should be exposed, and how developers should consume them without needing deep infrastructure expertise.
That means platform engineering is not useful because it is fashionable. It is useful because complexity has a cost, and somebody has to design a reliable interface to that complexity.
Why the old model starts breaking down
Small teams can often succeed with lightweight DevOps practices and a modest amount of shared tooling. But as the company grows, several failure modes appear at the same time:
- Every team builds slightly different pipelines and deployment conventions.
- Security and compliance requirements are implemented unevenly.
- Environment setup becomes slow and error-prone.
- Infra knowledge concentrates in a few people.
- Developers lose time navigating Kubernetes, IAM, networking, secrets, and CI/CD internals.
Google Cloud identifies this directly as cognitive load. Datadog makes the same point from the IDP angle: internal developer platforms improve developer experience by centralizing tools, APIs, infrastructure access, and documentation so teams can work against a coherent system rather than a pile of disconnected services.
This is the architectural reason platform engineering exists. The job is not merely to create a nicer dashboard. The job is to reduce variation in the delivery path while preserving enough flexibility for product teams to move.
What platform engineering actually builds
The core output of a platform team is usually an internal developer platform.
An IDP is not a single product SKU. It is the operating surface developers use to discover services, provision resources, deploy workloads, and follow approved workflows. In the sources reviewed here, that platform consistently includes the same building blocks:
- A software catalog or service inventory
- Self-service workflows for infrastructure and deployments
- Standardized templates or golden paths
- Governance controls and compliance checks
- Observability and feedback loops
- Access control and permissions
Datadog's overview is especially useful because it frames these as concrete platform capabilities, not vague platform promises. Golden paths matter because they give teams an opinionated default. Self-service matters because it removes routine waiting. Compliance matters because standards enforced in the platform are more reliable than standards documented in a wiki.
That is the critical shift: platform teams stop handing out raw tools and start shipping workflows.
Golden paths are opinionated, not restrictive
"Golden path" is one of those terms that sounds fluffy until you define it properly.
In practice, a golden path is a preferred way to do a common engineering task with guardrails already built in. It might be the approved path for creating a new service, provisioning a database, shipping a containerized app, or rolling out a preview environment. The path is "golden" not because it is mandatory in every case, but because it is reliable, documented, secure, and fast for the majority case.
Google Cloud explicitly ties platform engineering to golden paths. Datadog connects the idea to best practices and standardization. Together, those sources support the right interpretation: a golden path is a productized workflow that reduces decision fatigue without blocking legitimate edge cases.
That distinction matters because poorly designed platform programs often fail in one of two ways:
- They are too loose, so every team still does everything differently.
- They are too rigid, so teams route around the platform and reintroduce shadow infrastructure.
The platform team’s job is to avoid both extremes.
Developer portals and platform orchestrators are not the same thing
One of the most useful patterns in the Topic 2 source set is the distinction between the frontend interface and the backend control plane.
Humanitec's material describes a platform orchestrator as the backend logic of an IDP: deployment workflows, environment rules, resource provisioning, rollbacks, and audit trails. Port's write-up complements that by describing the portal as the frontend access point where developers perform key tasks independently. Humanitec's comparison piece makes the difference explicit: a developer portal like Backstage acts as the interface and service catalog, while an orchestrator handles configuration generation, deployment logic, and infrastructure execution behind the scenes.
That split is worth understanding because it corrects a common misconception. A company can deploy a developer portal and still not have a real platform. If the portal only surfaces documentation and service ownership data, but the hard operational steps still require manual intervention, the organization has improved visibility, not self-service delivery.
A credible internal platform usually needs both:
This is one implementation pattern rather than a universal law, but it is a useful mental model for evaluating platforms honestly.
What better looks like in real teams
A strong platform engineering effort changes the daily experience of software teams in specific ways:
- A developer can scaffold a service without rebuilding the same boilerplate choices each time.
- Environment creation becomes automated instead of ticket-driven.
- Infrastructure policies are embedded in the platform instead of manually enforced case by case.
- Teams can see service ownership, dependencies, and standards in one place.
- Platform changes happen through a maintained product surface rather than tribal knowledge.
Humanitec's use-case material repeatedly emphasizes governed self-service across environments. Datadog emphasizes unified access, scorecards, and standardization. Google Cloud emphasizes reduced human error through standardized paths. These are different vendor angles on the same underlying idea: platform engineering is about compressing operational complexity into a reusable product.
That is the right level of ambition. If your "platform initiative" is only a collection of scripts, you are still in the toolchain era.
When you should not build a platform team
Not every company needs a full platform engineering function.
This is where teams often get carried away. Platform engineering is expensive if you build it too early or build too much of it. Google Cloud is careful on this point: a dedicated platform effort makes sense when infrastructure friction is materially slowing application teams and when the cost of that friction exceeds the cost of building and maintaining the platform.
If your teams are small, your delivery model is simple, and your infrastructure needs are straightforward, lightweight automation may be enough. In that case, the correct move is usually:
- Improve CI/CD consistency
- Tighten documentation
- Standardize a few workflows
- Avoid creating a new internal product team prematurely
Platform engineering becomes justified when recurring platform work has clearly become a shared product problem rather than a set of isolated local annoyances.
A practical adoption path
Teams that get value from platform engineering usually do not start with a giant internal platform rewrite. They start with a narrow set of high-friction workflows and productize those first.
A pragmatic rollout looks like this:
Step 1: Identify the repeated pain
Look for patterns that repeatedly waste engineering time:
- Provisioning environments takes too long
- New services are created inconsistently
- Security controls differ by team
- Deployments require too much ops intervention
- Developers cannot find ownership or operational context easily
If the friction is not repeated, it is probably not platform work.
Step 2: Define one or two golden paths
Choose a high-frequency workflow and make it safe, fast, and boring. Good first candidates are:
- Create a new service
- Request a database or queue
- Spin up a preview environment
- Deploy a service to staging or production
This keeps the platform grounded in actual product value instead of abstract architecture.
Step 3: Separate interface from orchestration
Make an explicit design decision about the user-facing portal and the backend execution layer. The sources around Port, Backstage, and Humanitec are useful here because they demonstrate that discoverability and execution are different concerns. Treating them as one blob usually leads to poor abstractions.
Step 4: Build governance into the workflow
Do not bolt compliance on after adoption. Datadog highlights scorecards, compliance tracking, and RBAC as first-class IDP capabilities. Google Cloud makes the same case through built-in security and operational standards. If the platform does not enforce the expected path, teams will eventually drift.
Step 5: Measure adoption, not just platform output
A platform is only successful if developers actually use it. Self-service that nobody trusts is not self-service. Adoption, lead-time reduction, deployment consistency, and support-ticket deflection matter more than how many internal components the platform team shipped.
The real risk: building a platform nobody asked for
There is one recurring failure pattern worth naming directly. Some platform teams respond to complexity by building an elaborate internal abstraction layer that solves theoretical problems while adding new operational distance from the actual developers doing the work.
That is not platform engineering. That is internal product overreach.
The best platform teams behave like product teams:
- They define clear users.
- They solve frequent problems.
- They keep the interface simple.
- They maintain escape hatches.
- They measure trust and adoption.
Standardization without usability becomes bureaucracy. Self-service without guardrails becomes chaos. Good platform engineering sits in the middle and holds that line deliberately.
Summary
Platform engineering is best understood as the scalable operating model for DevOps, not its replacement.
DevOps gives organizations the culture of shared responsibility and automation. Platform engineering turns that culture into a reusable internal product through portals, orchestrators, golden paths, governance, and self-service workflows.
The real value is not the label. The value is reducing cognitive load, enforcing reliable standards, and giving developers a faster path to shipping software without forcing every team to become an infrastructure expert.
If your teams are still assembling bespoke delivery stacks by hand, you likely do not have a DevOps problem. You have a platform problem.
FAQ
Is platform engineering replacing DevOps?
No. The strongest primary source in this set, Google Cloud, frames platform engineering as an evolution that helps organizations achieve DevOps goals at scale. DevOps remains the cultural model. Platform engineering is the specialized implementation discipline.
What is an internal developer platform?
An internal developer platform is the set of tools, workflows, interfaces, and guardrails that helps developers provision infrastructure, deploy services, discover ownership information, and follow approved engineering paths through self-service.
What are golden paths in platform engineering?
Golden paths are opinionated, supported workflows for common tasks such as scaffolding services, provisioning infrastructure, or shipping deployments. They reduce variation and speed up delivery while preserving secure defaults.
Do I need both a developer portal and a platform orchestrator?
Not always as separate products, but you do need both concerns addressed. Developers need an interface for discovery and self-service, and the platform needs backend logic for configuration, provisioning, policy enforcement, and deployment execution.
When should a company invest in platform engineering?
Usually when infrastructure complexity, inconsistent delivery practices, and slow provisioning have become recurring organizational bottlenecks. If simple automation still works and teams are not overloaded, a full platform initiative may be premature.
Conclusion
The most important correction to make in this conversation is simple: platform engineering is not a rebrand for DevOps, and it is not an excuse to centralize everything behind another ticket queue.
It is the discipline of building a reliable internal product that turns good delivery principles into repeatable developer workflows.
For modern engineering teams, that usually means fewer bespoke pipelines, fewer one-off infrastructure decisions, better security defaults, and less time lost to avoidable operational complexity. If DevOps taught teams to own the path to production, platform engineering teaches organizations how to make that path usable at scale.
That is why golden paths matter. They are not just process. They are the interface to better engineering throughput.
