
Introduction
For the first wave of generative AI applications, prompt engineering was the center of gravity. If you could write the right instruction, provide a few examples, and tune the phrasing well enough, you could get surprisingly good results from a model. For single-turn tasks like classification, summarization, rewriting, and extraction, that was often enough.
It is still enough for many narrow use cases.
But once you move from one-shot text generation to production AI systems, especially agents, the problem changes. The model no longer needs just a clever prompt. It needs the right information, at the right time, in the right structure, with the right tools, while preserving enough memory to stay coherent across multiple steps. That is a different engineering problem.
Anthropic describes this shift clearly: prompt engineering focuses on writing and organizing instructions, while context engineering focuses on curating and maintaining the full set of tokens available during inference, including prompts, tools, message history, external data, and runtime state. That is why the move from prompt engineering to context engineering is not a branding exercise. It is a response to the actual failure modes teams hit in production.
If prompt engineering is about asking better questions, context engineering is about building a better information environment for the model.
Core Content
Where prompt engineering still works
Prompt engineering should not be dismissed. IBM's overview remains a useful reminder that prompting techniques such as zero-shot, few-shot, and chain-of-thought-style structuring still matter when the task is self-contained and the model already has what it needs.
That is the key boundary.
Prompt engineering works well when:
- The task fits in a single request-response cycle.
- The model can answer from its training and the provided prompt.
- The required logic is relatively static.
- The system does not need durable memory, tool use, or multi-step planning.
Neo4j's comparison makes a similar distinction. Prompt engineering performs well for summarization, translation, extraction, simple chat, and one-shot tasks where the context is stable and limited.
This is why prompt engineering is still part of production AI. It just is not the whole system anymore.
Where prompt engineering breaks down
As soon as the system has to remember, retrieve, decide, and act across multiple steps, prompt quality stops being the main bottleneck.
Neo4j describes the failure pattern well: prompts become huge, brittle, and unmanageable as teams try to compensate for missing runtime context with more instructions. The model forgets earlier details, tool guidance gets buried in noise, and long workflows drift off course.
Anthropic frames the same problem in terms of finite context. Context is not an unlimited asset just because models support longer windows. It is a constrained resource with diminishing returns. More tokens can help, but only if those tokens are relevant and well organized.
This is the operational limit of prompt-only thinking. A better prompt cannot fully solve:
- Missing runtime data
- Evolving task state
- Long message histories
- Too many tools with overlapping behavior
- Contradictory or outdated information
- Multi-step plans that need selective memory
Once those problems appear, the correct response is architectural, not rhetorical.
What context engineering actually means
Elastic offers a useful baseline definition: context engineering is a collection of practices used to provide the right information to a large language model so it can complete the desired task.
That may sound broad, but that breadth is exactly the point. Context engineering is not one technique. It is the design of the model's information boundary.
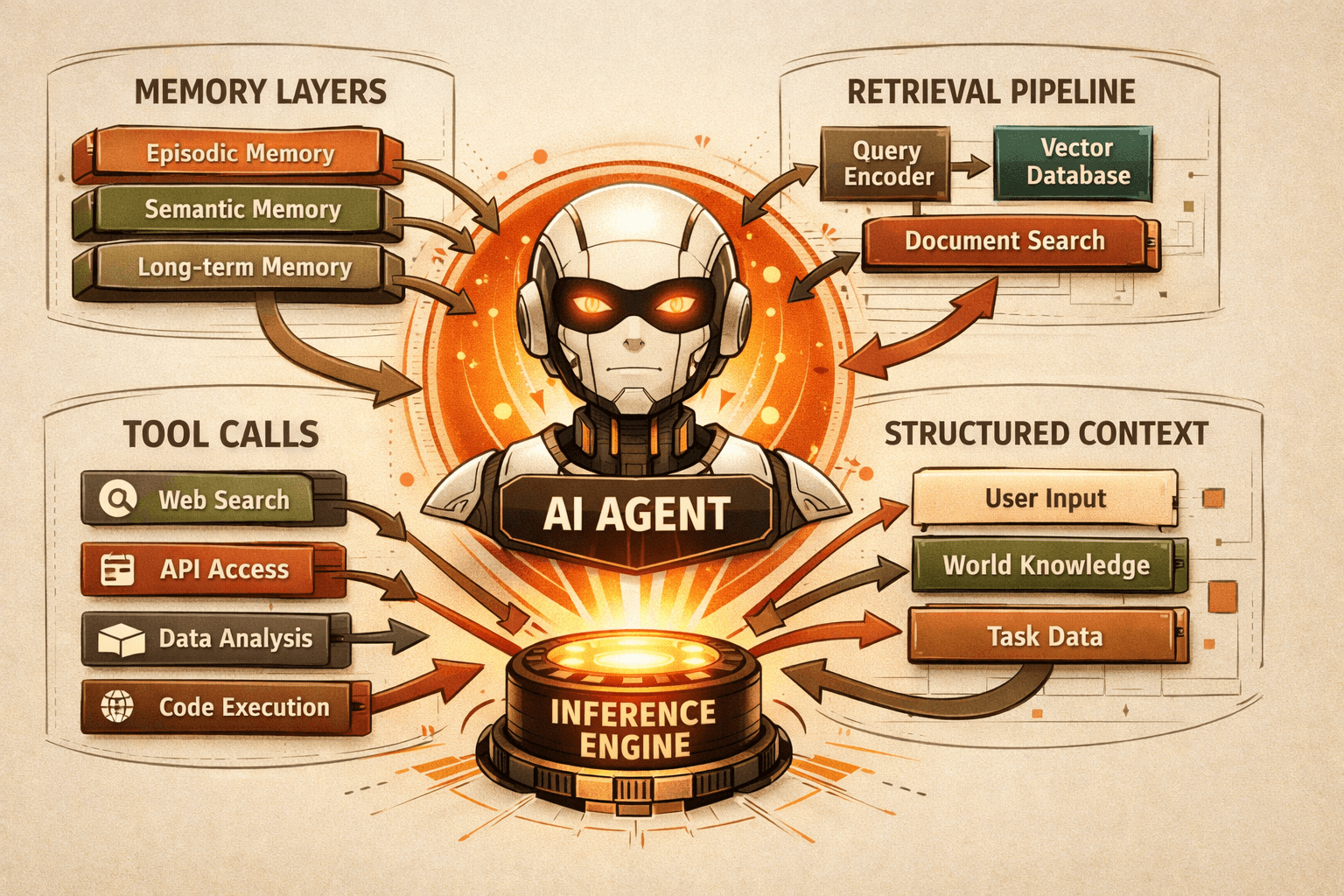
In production systems, that usually includes:
- System instructions
- Retrieved documents
- Conversation history
- Short-term and long-term memory
- Tool definitions and tool outputs
- Structured output constraints
- External runtime state
Anthropic's engineering article pushes this further by framing context engineering as an iterative curation process. Each turn of an agent loop requires deciding what the model should see next from a much larger universe of possible information.
That is a better mental model than "better prompts." You are not just composing text. You are managing a stateful information budget.
The core components of a production context pipeline
The fastest way to make context engineering concrete is to break it into components.
Prompts and system instructions
Prompts still matter, but Anthropic argues for clear, minimal, well-structured instructions rather than giant prompt monoliths. The useful principle is not maximal detail. It is the smallest amount of high-signal guidance that reliably produces the desired behavior.
That means:
- Separate background, instructions, tool guidance, and output requirements
- Avoid brittle if-else logic in prompts
- Use examples selectively rather than dumping edge cases into the context
This is still prompt engineering, but now it is treated as one layer of the system.
Retrieval and RAG
Elastic highlights Retrieval-Augmented Generation, or RAG, as one of the key components of context engineering. The reason is straightforward: when the model needs grounded information, it should receive the relevant subset instead of being forced to rely on pretraining or overloaded with full corpora.
This matters even more as context windows get larger. Elastic explicitly pushes back on the idea that larger windows make retrieval irrelevant. More raw information can create what it calls context confusion, where too much material degrades the result rather than improving it.
The practical implication is simple: retrieval is still valuable, but it has to be selective and relevant.
Memory and state
Elastic separates memory into short-term and long-term forms. Short-term memory is the current conversation state. Long-term memory spans across conversations or stores persistent user, task, or system knowledge.
That distinction is foundational for agents.
If everything lives in the immediate prompt, the system becomes fragile and expensive. If nothing is persisted externally, the model cannot stay coherent across longer workflows. Good context engineering defines what should stay in working memory, what should be persisted, and what should be reloaded only when needed.
Anthropic's guidance on structured note-taking fits here. For long-running tasks, agents need a persistent place to store decisions, unresolved items, and progress markers outside the active context window. That external memory is often the difference between an agent that finishes a task and one that repeatedly loses the plot.
Tools and tool outputs
Anthropic is especially strong on tool design. Tools are not just capabilities. They are part of the context boundary because they define how the model can observe and act on the world.
Poor tool design creates poor context.
If multiple tools overlap, return bloated payloads, or use ambiguous parameters, the model wastes tokens and makes weaker decisions. Anthropic recommends tools that are self-contained, clear, and minimal, with descriptive parameters and limited overlap.
Elastic reaches a similar conclusion from another angle: context engineering should minimize tool explosion and encourage one tool per job when possible.
This is a useful engineering rule. A tool is not good because it is powerful. A tool is good because the model can choose and use it reliably.
Structured outputs and schemas
Elastic also emphasizes schemas. If you expect the model to produce specific outputs or interact with tools safely, structure matters.
Schemas reduce ambiguity in two places:
- What the model receives
- What the model is allowed to produce
That improves downstream reliability, especially in automation-heavy systems where free-form text is harder to validate and route.
The failure modes context engineering is trying to prevent
The phrase "context engineering" only matters if it helps avoid concrete failure modes. The source set surfaces four that are worth naming directly.
Context rot
Anthropic cites research and field experience showing that as context grows, models can lose focus. Neo4j calls this context rot: the window gets larger, but attention becomes diluted and accuracy drops because the model struggles to identify what matters.
This is the strongest argument against the naive strategy of "just put everything in the prompt."
Context poisoning
Elastic describes context poisoning as the result of malicious or accidental contamination of the context. That includes prompt injection and data poisoning, but it also includes something more ordinary: outdated, irrelevant, or contradictory information building up over time and distracting the model.
In other words, bad context is not always adversarial. Sometimes it is just unmanaged history.
Prompt bloat
This is what happens when teams respond to every failure by adding more instructions, more examples, and more caveats to a single master prompt. The prompt gets bigger, harder to maintain, and less legible, while the model's actual behavior becomes less predictable.
Prompt bloat is often a signal that the system needs better retrieval, memory, or tooling rather than more prose.
Tool confusion
Anthropic points out a common failure mode: if a human cannot clearly tell which tool should be used in a situation, the model probably cannot either. Tool confusion wastes tokens, misroutes actions, and lowers confidence in the system.
This is usually a design failure, not a model failure.
A practical architecture for context engineering
If you are moving from prompt experiments to production agents, the right move is not to memorize new terminology. It is to make better architectural decisions.
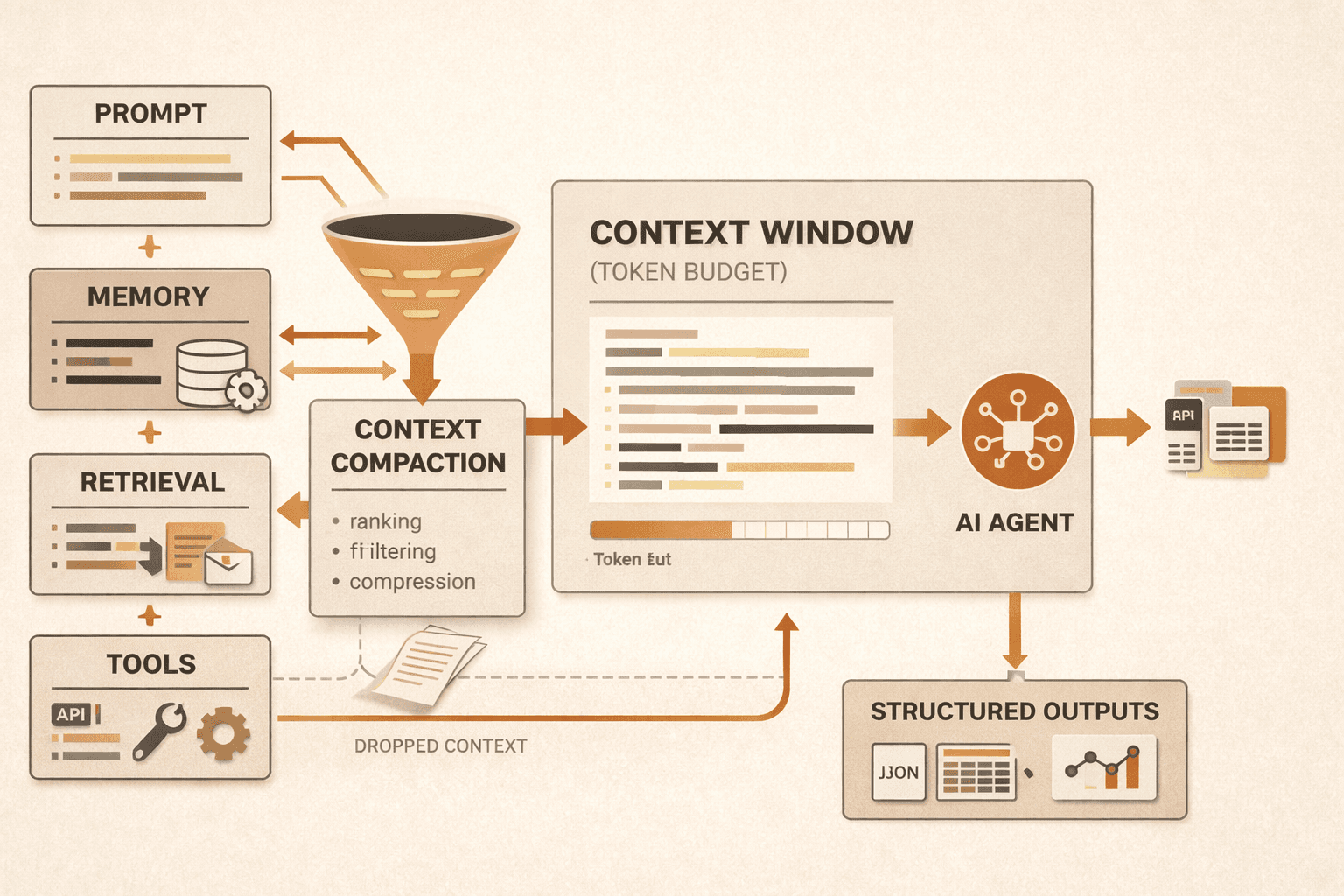
A practical context pipeline usually includes the following steps.
Step 1: Define the minimum viable context
Before choosing a framework or retrieval stack, identify the smallest set of information the model needs to complete the task reliably. Anthropic's overall guidance is to keep context informative but tight. That principle scales well.
If you cannot explain what information is essential, you are not ready to optimize it.
Step 2: Separate persistent memory from working memory
Use short-term context for the active turn and external memory for durable state. That may include user preferences, task notes, previous decisions, or long-lived facts.
Elastic's short-term versus long-term memory distinction is useful here because it prevents teams from treating every fact as equally urgent. Most information should not sit in the active window all the time.
Step 3: Retrieve just in time
Anthropic describes a just-in-time retrieval pattern where agents keep lightweight references such as file paths, queries, or links and pull data into context only when needed. That approach reduces prompt bloat and helps the model stay focused on the current subtask.
This is one of the most important shifts in agent design. Instead of preloading everything, let the system discover relevant context progressively.
Step 4: Use a hybrid retrieval model when appropriate
Anthropic also recommends hybrid strategies in some environments: preload a small amount of high-value context for speed, then allow the agent to explore or fetch more data as needed.
That is often a better production default than choosing between "all up front" and "all on demand."
Step 5: Compact aggressively, but not blindly
For long-horizon tasks, Anthropic recommends compaction: summarize a nearly full context window into a high-fidelity summary and continue from there. It also notes a lower-risk tactic, clearing old tool results that no longer need to remain verbatim in context.
This is an area where teams need rigor. Compaction that loses critical details creates silent failures. Compaction that keeps everything is not compaction.
Step 6: Evaluate traces, not just outputs
A final answer might look acceptable while the underlying context pipeline is weak. Neo4j and Elastic both point toward evaluation at the retrieval and context level, not only at the output layer.
For production systems, inspect:
- What information was retrieved
- What the agent ignored
- Which tools it selected
- Whether memory was reused correctly
- Where irrelevant or conflicting information entered the flow
That is how context engineering becomes an engineering discipline instead of a slogan.
Prompt engineering still matters, but as a layer
The simplest way to avoid confusion is to stop framing prompt engineering and context engineering as opposites.
Prompt engineering remains important for:
- Clear system instructions
- Format guidance
- Output constraints
- Example selection
- Safety boundaries
But once the system is dynamic, prompt engineering becomes a component within a larger architecture. Prompt quality still matters. It just no longer determines reliability by itself.
That is the real shift behind the term. The frontier has moved from "What should I write?" to "What should the model know right now, and how should it get that knowledge?"
Summary
Prompt engineering is still useful, but production AI systems demand more than well-written instructions.
Context engineering is the broader discipline of deciding what information enters the model's context, when it enters, how it is structured, how long it persists, and how the model can access more of it through tools and retrieval.
For agents and other multi-step systems, that means building around memory, RAG, tool design, schemas, compaction, and evaluation. The teams that do this well are not just writing better prompts. They are designing better context pipelines.
FAQ
Is context engineering replacing prompt engineering?
Not completely. Prompt engineering is still a useful skill for structuring instructions and examples. Context engineering is broader. It includes prompts, but also retrieval, memory, tools, schemas, and runtime state management.
What is context rot?
Context rot is the degradation that happens when a model is overloaded with too much or poorly organized information. Even with large context windows, attention becomes diluted and the model struggles to identify what matters.
Does larger context mean I no longer need RAG?
No. Elastic's overview explicitly argues that larger context windows do not eliminate the need for selective retrieval. Dumping more documents into the window can produce context confusion instead of better answers.
What is the difference between short-term and long-term memory in AI agents?
Short-term memory is the active conversation or current task state inside the immediate context window. Long-term memory is persistent information stored outside the current window and reintroduced when needed.
What is the safest first step toward context engineering?
Define the minimum viable context for one workflow, then decide what should be prompt content, retrieved data, external memory, and tool output. Start narrow and evaluate traces before expanding the system.
Conclusion
The most useful way to understand context engineering is as a maturity shift in AI application design.
Early systems could get far with a smart prompt because the task was narrow and the interaction was short. Production systems operate in a different environment. They need memory, retrieval, tool use, state, and clear control over what the model sees from one step to the next.
That is why context engineering matters. It turns model interaction from a wording problem into a systems problem.
And that is a good thing. Systems problems can be measured, designed, and improved.
